В практике обработки DJVU-копий книг иногда встречаются случаи, когда в файле
отсутствует текст оглавления или оглавление есть, но в его строках отсутствуют
номера страниц, на которой расположен данный раздел. Если книга большая, 1000 или
более страниц и текст ее хорошо структурирован, так что оглавление ее содержит
несколько сотен строк и восстанавливать такое оглавление "вручную" очень долго и
работа очень утомительна. Возникает задача его программного восстановления.
Здесь мы изложим два метода восстановления, которые неоднократно успешно
применяли. Оба метода основаны на обработке текстов страниц
DJVU-книги, полученных путем распознавания их изображений. В одном методе
используется результат распознавания,
запомненный в форма txt, в другом ---
htm.
Иллюстрировать будем на примере файла Handbook_of_Matrices.djvu. Это копия книги "HANDBOOK OF MATRICES",H. Lutkepohl.
Последовательность шагов следующая:
1. Преобразуем формат bunde djvu в
формат indirect djvu.
2. Из каждого страничного файла
djvu извлечем OCR-слой текста и запомним его в
тестовый с тем же именем.
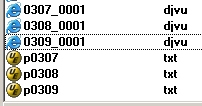
Ниже показаны три файла, представляющие копии страниц 307, 308, 309 из указанной книги и соответствующие текстовые файлы.
Детали выполнения пунктов 1 и 2 мы опускаем, считая, что читатель знаком с технологией обработки DJVU файлов.
Итак, мы имеем множество текстовых файлов, представляющих собой тексты страниц
Djvu-копии. В именах файлов присутствует число,
отображающее номер страницы книги (или номер этой страницы в файле
djvu).
Далее:
3. программой Search and Replace for Windows, используя регулярные выражения,
ищем
во всем множестве файлов контекст, структурного номера раздела, например,"^[0-9].[0-9]+[]$" , т.е.
ищем строки,
текста, начинающие с текста
<любая цифра><точка><любая цифра><пробел>
и далее содержащие любой набор символов.
4. Запоминаем результат работы программы. Это будет текстовый файл, например,
Result1.txt.
5. повторяем пункты 3 и 4 для контекста "^[0-9][0-9].[0-9]+[]$",Result2.txt
В зависимости от глубины структуры дерева оглавления регулярные выражения для поиска могут быть расширены,
например, "^[0-9][0-9].[0-9].[0-9]+[]$" и т.п.
6. Объединяем файлы Result1 и Result2 в один файл Result.txt
Ниже приведен вид фрагмента этого файла.
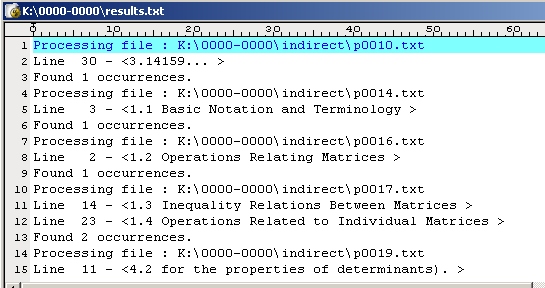
Обращаем внимание на два типа строк этого файла.
В строках, начинающихся с текста "Processing
file:", содержится текст имени файла, где
найден искомый текст.
В строках, начинающихся с текста "Line
:", содержится строка
, которая содержит этот искомый текст..
7. Запускаем программу number_insertion и обрабатываем файл Result.txt этой программой .
Эта программа читает число из текста имени файла и вставляет его в конец всех строк этого файла, содержащих искомый контекст. Программа записывает в файл только строки, с найденным контекстом. Имя этого файла формируется путем добавки к имени исходного файла префикса "R_".
Ниже приведен вид этого файла.
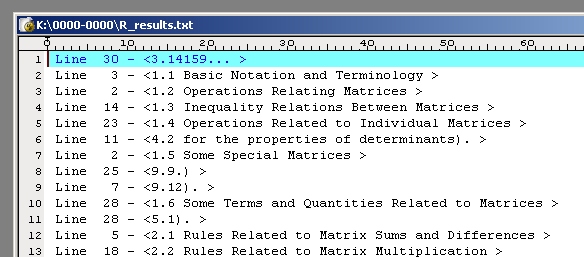
Обращаем внимание, что номера строк не видны, они записаны в позиции 200.
8. Запустим программу Search and Replace for Windows, используя регулярное выражение
"Line+[]-",
совершим подстановку пустой строки, чтобы удалить текст "Line ...."
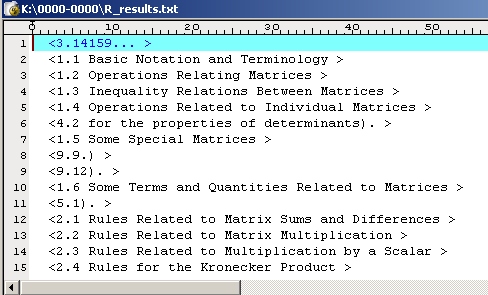
На скриншоте, приведенном выше, в угловых скобках показан найденный контекст.
9. Теперь удалим угловые скобки , вставленные номера страниц в 200-й позиции скопируем в первую позицию и удалим лишние пробелы. После этих операций файл примет вид :
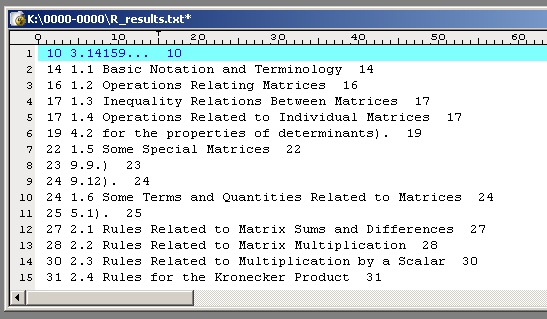
Зачем надо было копировать номера страниц ?. Для данного примера это лишнее. Но если бы мы искали еще и контексты например "^Глава [0-9]+[]$" , то в объеденном файле результатов строки не были бы упорядочены по номерам страниц. В этом случае номера в начале строке пригодились бы для их упорядочения.
10. Просматриваем файл и удаляем строки, не относящиеся к оглавлению . Удаляем лишние номера страниц в началах строк. В итоге получаем черновик оглавления. Осталось только вставить строки с названиями глав. Конец.
Анализ книг показывает, что названия разделов книги практически всегда печатаются жирным шрифтом и его размер всегда больше, чем размер шрифта обычного текста, которым напечатана книга. В книгах типа словарей названия словарных статей также всегда выделяются жирным шрифтом. При этом в названиях статей размер шрифта может совпадать с размером шрифта основного текста.
Поэтому возникла идея использовать эти свойства для восстановления оглавлений из текста книги и для индексирования названий словарных статей в словарях, тексты которых представимы в коде ASCII.
Итак, имеем множество файлов изображений страниц книги. Их имена содержат числа, указывающие на номера страниц.
1. Распознаваем текст с помощью программы FineReader 8. При решении задачи восстановления оглавления результаты сохраняем в htm-файлах с именами исходных изображений в простом формате ( совместимым со всеми браузерами); при индексировании фрагментов текста, напечатанного жирным шрифтом, сохранение производим в полном формате ( с применением CSS).
2. Запускаем программу Bolds_text_out_htm.
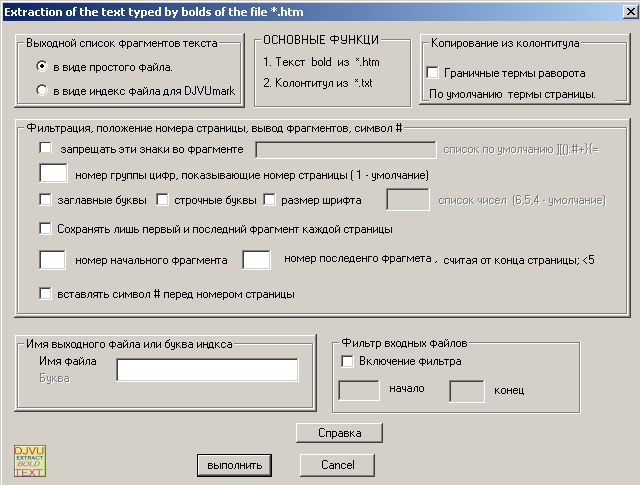
3. Анализируем выходной файл. Принимаем решение какой фильтр надо использовать, чтобы отсеять ненужную информацию. Выбираем соответствующие опции программы и выполняем пункт 2.
При обработке файлов для книги Spectral theory and nonlinear functional analysis c опцими "размер шрифта" и без "запрещения некоторых символов во фрагменте" был получен следующий файл. После применения опции запрещения символов из списка по умолчанию результат был значительно улучшен.. Из полученного текста видно, что текст оглавления требует минимального редактирования: необходимо убрать несколько лишних строк и отредактировать строки, относящиеся к названиям глав.
Предметный указатель к словарю American IDIOMS Dictionary Richard ,A. Spears был получен с помощью программы Bolds_text_out_htm. Предметный указатель был получен в двух версиях. По указанной выше ссылке приведена полная версия указателя, т.е представлены все названия словарных статей на каждой странице словаря. Во второй версии указателя из всего множества названий, которые имеются на каждой странице, извлекались только два названия словарных статей: первое и последнее, т.е. та информация, которая обычно содержится в колонтитулах словаря. Именно по такому принципу был сформирован предметный указатель к трех томному изданию академического словаря "Русско-украинский словарь". Например, фрагмент названий словарных статей, начинающиеся на букву "A" Предметный указатель к этому словарю можно преобразовать в формат DicView для программы BookmarkTool-2.0. Для текст предметного указателя необходимо оформить как структуру Словарь. Полученный файл bookmarks.htm после обработки структуры Словарь программой DJVUmark надо преобразовать утилитой Index_dicview_format. Об этом смотрите ниже.
В заключение, одно существенное замечание. Программа Bolds_text_out_htm обрабатывает программно распознанный текст. Это текст практически всегда содержит ошибки при любом разрешении изображения. Это либо неправильно распознанный текст или ошибки в оформлении формата. К примеру фрагмент A bird in the hand is worth two in the bush, в упомянутом словаре в файле htm был представлен следующим образом: <b>A bird in the hand is worth two in the </b><span style=" letter-spacing:-0.15pt;"><b>bush, </b>. Почему-то фрагмент оказался разбитым на два фрагмента и Bolds_text_out_htm извлекла два фрагмента. Формально все правильно. Можно привести примеры, когда текст напечатан обычным шрифтом, а программа FineReader 8 рассматривает его как жирный. Поэтому ошибки программы Bolds_text_out_htm состоять из собственных ошибок + ошибки программ распознавателей текста. Это замечание относится ко всем программам, работа которых связана с тестами, полученных программами OCR. Вот почему автор этих строк с крайним недоверием относится и к программе DjVuHypEdit( перед использованием слишком много надо делать проверок DJVU, чтобы получить надежный результат).
Таким образом, программа выдает не готовый чистовой вариант продукта, а черновик, требующий дальнейшей обработки. Эксперименты с толковыми англо-язычными словарями показали хорошие результаты в том смысле, что в дальнейшем потребовалось минимальное редактирование текста. Плохие результаты были получены со словарем "Толковый словарь русского языка" ред. Д.В. Дмитриева, хотя разрешение на Djvu странице 600 dpi. Результат распознавания содержал слишком много ошибок(возможно из-за того, что использовались изображения, извлеченные из DJVU-формата ).
В программе WinDjView-0.5 кроме оглавления (contents) появилась возможность введения индекса (index). Этот новый инструмент ориентирован на словари. Индекс содержит не все названия словарных статей. В каждую строку индекса из всех словарных статей, размещенных на странице, помещаются только два названия словарных статей: первое название и последнее название. В качестве формата ввода информации используется таблица программы EXCEL
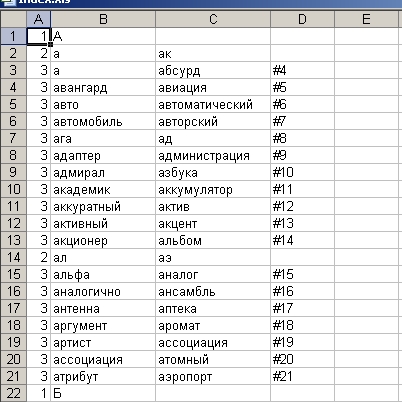
Как видим, структура дерева описывается числами в первой позиции, указывающими глубину структурного элемента. Примерно так описывается структура дерева bookmark программе DjVu Fancy Viewer.
Информация о первом и последнем названиях словарных статей, находящихся на данной странице словаря, и номер этой страницы, которые используются в строках таблицы EXCEL, могут быть получены из файла Djvu словаря, используя программу Bolds_text_out_htm. В качестве примера смотрите файл a_Index_e.txt.
Файл bookmarks.htm генерирует DJVUmark с параметром "Только оглавление" .
Оглавление имеет особую структуру. Использует только ключевые слова: СЛОВАРЬ,
БУКВА и СЕГМЕНТ и признак конца СЛОВАРЯ . СЛОВАРЬ состоит из структур БУКВА.
БУКВА содержит термы и/или структуры СЕГМЕНТ. Он состоит из термов словаря.
Синтаксис структур СЛОВАРЬ, БУКВА и СЕГМЕНТ следующий :
СЛОВАРЬ <название> , например, Русско-украинский словарь
БУКВА <название буквы> , например, БУКВА Б
СЕГМЕНТ <начало> <%> <конец> , например, СЕГМЕНТ ба % бк
Термы это первый и последний термы на странице и номер этой страницы ,
например, буквенный % бытующий 22
же дано описание в этом формате словаря "Русско-украинский словарь"
СЛОВАРЬ Русско-украинский словарь
Буква А
А % баловатъся 9
Буква Б
СЛОВАРЬ, БУКВА и СЕГМЕНТ
буквенный % бытующий 22
Буква В
СЕГМЕНТ ва % вл
важнейший % вверенный 22
вверить % ведь 23
взывать % виселица 28
висеть % влюбчивый 29
СЕГМЕНТ вм % вь
вменять % вовлекать 30
вовне % возвышена ость 31
вышеупомянутый % вьющийся 39
Буква Г
..................................
Буква Я
// @
Если приведенный выше фрагмент описания словаря вставить в качестве оглавления программу DJVUmark, то эта программа сгенерирует следующий файл bookmarks.htm .
На нашей странице представлена утилита index_dicview_format, предназначена для преобразования bookmarks.htm в текстовый файл формата DicView.
После обработки файла bookmarks.htm программой index_dicview_format получаем следующий файл R_bookmarks.txt. Теперь если импортировать это файл в пустую таблицу EXCEL ( в качестве разделителя таблицы используется символ %), то получим файл, который с помощью программы BookmarkTool-2.0 можно внедрить в файл DJVU.
Выполненные по данной методике примеры внедрения индексов словарей в файл файл DJVU показывают, что порядка 90% работы можно сделать программным путем и тем самим сократить огромную часть рутинной ручной работы.